
Um pouco de contexto sobre isso grande pacote de ensaios: Estudantes de todo o país escreveram originalmente essas redações entre 2015 e 2019 como parte de exames padronizados estaduais ou avaliações em sala de aula. A tarefa deles era escrever uma redação argumentativa, como “Os alunos devem ter permissão para usar celulares na escola?” As redações foram coletadas para ajudar cientistas a desenvolver e testar avaliações automatizadas de escrita.
Cada uma das redações foi classificada por avaliadores especialistas em escrita em uma escala de 1 a 6 pontos, sendo 6 a pontuação mais alta. A ETS pediu ao GPT-4o para pontuá-las na mesma escala de seis pontos usando o mesmo guia de pontuação que os humanos usaram. Nem o homem nem a máquina foram informados sobre a raça ou etnia do aluno, mas os pesquisadores puderam ver as informações demográficas dos alunos nos conjuntos de dados que acompanham essas redações.
O GPT-4o marcou as redações quase um ponto abaixo do que os humanos. A pontuação média entre as 13.121 redações foi de 2,8 para o GPT-4o e 3,7 para os humanos. Mas os asiático-americanos foram reduzidos em um quarto de ponto adicional. Os avaliadores humanos deram aos asiático-americanos uma média de 4,3, enquanto o GPT-4o deu a eles apenas 3,2 — uma dedução de aproximadamente 1,1 ponto. Em contraste, a diferença de pontuação entre humanos e o GPT-4o foi de apenas cerca de 0,9 pontos para alunos brancos, negros e hispânicos. Imagine um caminhão de sorvete que continuasse raspando um quarto de bola extra apenas dos cones de crianças asiático-americanas.
“Claramente, isso não parece justo”, escreveram Johnson e Zhang em um relatório não publicado que compartilharam comigo. Embora a penalidade extra para os asiático-americanos não fosse terrivelmente grande, eles disseram, é substancial o suficiente para que não deva ser ignorada.
Os pesquisadores não sabem por que o GPT-4o emitiu notas mais baixas do que os humanos, e por que ele deu uma penalidade extra aos asiático-americanos. Zhang e Johnson descreveram o sistema de IA como uma “enorme caixa preta” de algoritmos que operam de maneiras “não totalmente compreendidas por seus próprios desenvolvedores”. Essa incapacidade de explicar a nota de um aluno em uma tarefa de redação torna os sistemas especialmente frustrantes de usar nas escolas.
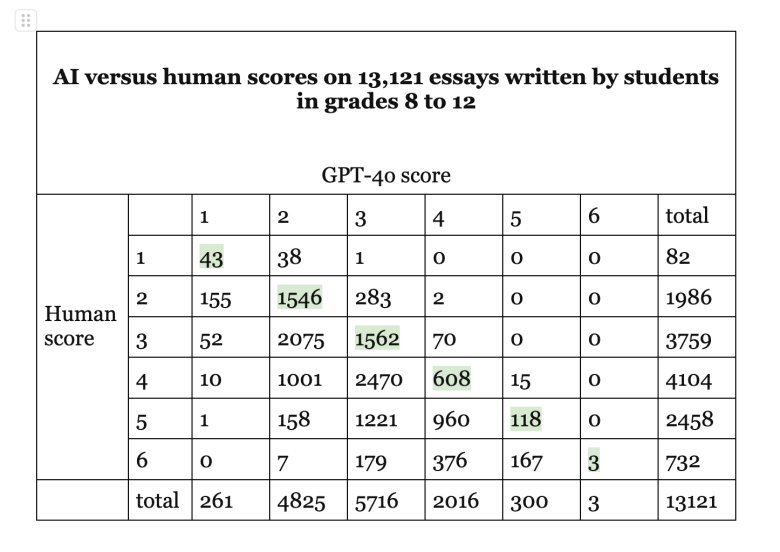
Este estudo não é prova de que a IA está consistentemente subestimando ensaios ou tendenciosa contra os asiático-americanos. Outras versões da IA às vezes produzem resultados diferentes. Uma análise separada da pontuação de ensaios por pesquisadores da University of California, Irvine e da Arizona State University descobriu que As notas das redações de IA eram tão frequentemente altas quanto baixas. Esse estudo, que usou a versão 3.5 do ChatGPT, não analisou os resultados por raça e etnia.
Fiquei pensando se o preconceito da IA contra os asiáticos-americanos estava de alguma forma conectado a altos desempenhos. Assim como os asiáticos-americanos tendem a tirar notas altas em testes de matemática e leitura, os asiáticos-americanos, em média, foram os escritores mais fortes neste pacote de 13.000 redações. Mesmo com a penalidade, os asiáticos-americanos ainda tiveram as maiores notas nas redações, bem acima das dos alunos brancos, negros, hispânicos, nativos americanos ou multirraciais.
Tanto no estudo de redação do ETS quanto no da UC-ASU, a IA concedeu muito menos notas perfeitas do que os humanos. Por exemplo, neste estudo do ETS, os humanos concederam 732 6s perfeitos, enquanto o GPT-4o deu um total geral de apenas três. A mesquinharia do GPT com notas perfeitas pode ter afetado muitos asiáticos americanos que receberam 6s de avaliadores humanos.
Os pesquisadores da ETS pediram ao GPT-4o para pontuar as redações friamente, sem mostrar ao chatbot nenhum exemplo classificado para calibrar suas pontuações. É possível que algumas redações de amostra ou pequenos ajustes nas instruções de classificação, ou prompts, dados ao ChatGPT possam reduzir ou eliminar o preconceito contra os asiático-americanos. Talvez o robô fosse mais justo com os asiático-americanos se fosse explicitamente solicitado a “dar mais 6s perfeitos”.
Os pesquisadores do ETS me disseram que esta não foi a primeira vez que notaram que estudantes asiáticos eram tratados de forma diferente por um robô-avaliador. Avaliadores de redações automatizados mais antigos, que usavam algoritmos diferentes, às vezes faziam o oposto, dando aos asiáticos notas mais altas do que os avaliadores humanos. Por exemplo, um sistema de pontuação automatizado do ETS desenvolvido há mais de uma década, chamado e-rater, tendia a inflar as pontuações de estudantes da Coreia, China, Taiwan e Hong Kong em suas redações para o Teste de Inglês como Língua Estrangeira (TOEFL), de acordo com um estudo publicado em 2012. Isso pode ter ocorrido porque alguns estudantes asiáticos memorizaram parágrafos bem estruturados, enquanto os humanos notaram facilmente que as redações estavam fora do assunto. (O Site da ETS diz que depende apenas da pontuação do avaliador eletrônico para testes práticos e a usa em conjunto com pontuações humanas para exames reais.)
Os asiático-americanos também obtiveram notas mais altas com um sistema de pontuação automatizado criado durante uma competição de codificação em 2021 e alimentado por BERT, que tinha sido o algoritmo mais avançado antes da geração atual de grandes modelos de linguagem, como GPT. Cientistas da computação colocaram seu robo-grader experimental em uma série de testes e descobriram que ele deram pontuações mais altas do que os humanos às respostas abertas dos asiáticos americanos em um teste de compreensão de leitura.
Também não ficou claro por que o BERT às vezes tratava os asiático-americanos de forma diferente. Mas ilustra o quão importante é testar esses sistemas antes de liberá-los nas escolas. Com base no entusiasmo dos educadores, no entanto, temo que esse trem já tenha partido da estação. Em webinars recentes, vi muitos professores postarem na janela de bate-papo que já estão usando o ChatGPT, o Claude e outros aplicativos com tecnologia de IA para avaliar a escrita. Isso pode economizar tempo para os professores, mas também pode estar prejudicando os alunos.















{kind=link}